ปัญหา คุณได้ข้อมูลมาชุดหนึ่ง ข้อมูลนี้มีสองส่วนประกอบ ส่วนแรกเป็นค่าที่ไว้ใช้อ้างอิง เป็นเลขจำนวนเต็ม มีค่า k (0 <= k <= 5e11) และอีกส่วนคือข้อมูลที่ต้องการเก็บ เป็นจำนวนเต็ม v (1 <= v <= 300) โดยจะมีจำนวนข้อมูล n ข้อมูล (1 <= n <= 1e5)
ในความคิดแรกเราอาจจะอยากใช้อาเรย์ในการเก็บค่าคีย์อ้างอิง (k) เอาไว้ โดยข้อมูล vi ก็เก็บในอาเรย์ใน index ที่ ki ถ้าเป็นแบบนี้แล้วก็จะเข้าถึงข้อมูลได้ใน O(1)
- int storage[500000000000];
- void add_val(long long key, int val) {
- storage[key] = val;
- }
- int get_val(long long key) {
- return storage[key]; // if not found return 0
- }
ปุจฉา : วิธีนี้ทำได้จริงเหรอ?
ลองประกาศอาเรย์ขนาด 5e11 ตัวดูนะ แล้วจะรู้ว่ามันเป็นไปไม่ได้ ! ขนาดมันใหญ่เกินไป เราจึงมีวิธีแก้ปัญหาที่สอง ก็ประกาศตัวแปรเท่าที่ใช้นั่นแหละ แล้วเก็บทั้งคีย์และค่า เวลาหาก็ไล่หาไปจนเจอคีย์ที่ตรงกับที่เราต้องการ
- typedef struct {
- long long key;
- int val;
- } DATA;
- DATA storage[10000];
- int last = 0;
- void add_val(long long key, int val) {
- storage[last].key = key;
- storage[last].val = val;
- last++;
- }
- int get_val(long long key) {
- for (int i=0; i<last; i++) {
- if (storage[i].key == key)
- return storage[i].val;
- }
- return 0; // not found
- }
ด้วยวิธีนี้การหาข้อมูลจะใช้เวลา O(n) ซึ่งก็เป็นตัวเลขที่ยอมรับได้ในกรณีที่ n มีค่าไม่เยอะเท่าไหร่ และเรียกใช้แค่ครั้งเดียว
สมมุติ 1<= n <= 1e6 และมีการเรียกใช้สัก 1 <= q <= 1e6 ครั้งล่ะ
O(qn) -> 1e12 ไม่ใช่ตัวเลขที่น่ารักเลยสำหรับการเขียนโปรแกรมเชิงแข่งขัน และการเขียนโปรแกรมจัดการฐานข้อมูลในโลกจริงเช่นกัน ลองนึกภาพ Facebook ใช้เวลา O(qn) ในทุกการค้นหาของผู้ใช้สิ ด้วยปริมาณข้อมูลขนาดนั้นคงต้องรอสักครึ่งวันแน่ ๆ ในการแอบส่องเฟสผู้ฯสักคน 'w')b
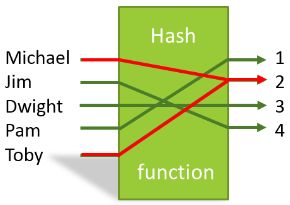
รูปที่ ๑ ภาพแสดงการ hash string เป็น int
นี่จึงเป็นจุดที่เราต้องใช้ไสยศาสตร์เข้ามาช่วย มันเรียกว่า Hash function ซึ่งจะเขียนอย่างไรนั้นก็แล้วแต่ประเภทของข้อมูลและวิธีการใช้ และถึงจะเป็นข้อมูลเดียวกัน การใช้งานเดียวกัน การ hash ก็ทำได้หลากหลายวิธีมาก เรียกได้ว่าขึ้นกับความคิดสร้างสรรค์ของคนเขียนเลยก็ว่าได้
นี่เป็นตัวอย่างการ hash ที่หน้าโง่มาก ๆ (แต่ก็ใช้งานได้ในระดับหนึ่ง)
- #define MAX 10000 //n<=10000
- static const int magic 19;
- return (key+magic)%MAX;
- }
ปุจฉา : ฟังก์ชั่นนี้ทำอะไร
ฟังก์ชัน hash แบบขี้เกียจสุด ๆ นี้นำเลขคีย์มาบวกด้วยเลขไสยศาสตร์อะไรสักอย่าง และนำไปหารเอาเศษด้วยจำนวนข้อมูลที่สามารถเก็บได้ (n) มาดูตัวอย่างกันดีกว่า
hash(0) = 19,
hash(219302) = 9321,
hash(2093139432333) = 2352
สังเกตุได้ว่า เนื่องจากสุดท้ายเรานำคีย์ที่ผ่านพิธีกรรมเลขไสยศาสตร์ของเรามาแล้วไปหารเอาเศษกับ n ในที่นี้คือ 10000 ดังนั้นค่าที่ออกมาก็จะอยู่ในช่วง 0-9999
ฉะนั้นแล้วเราย่อมเก็บข้อมูลไว้ในอาเรย์ขนาด 10000 ตัวได้ไม่ว่าเลขคีย์จะเยอะแค่ไหนก็ตาม และการคำนวนนี้ใช้เวลา O(1) และการหาก็คือการเอาคีย์ไปใส่ใน hash เพื่อให้ได้เลขตำแหน่งที่เก็บออกมา นั่นก็ O(1) เหมือนกัน !
- #defind MAX 100000
- int hash(long long key) {
- static const int magic 19;
- return (key+magic)%MAX;
- }
- int storage[MAX];
- void add_val(long long key, int val) {
- storage[hash(key)] = val;
- }
- int get_val(long long key) {
- return storage[hash(key)]; // if not found return 0
- }
ปุจฉา : วิธีนี้ทำได้จริงเหรอ?
ลองกลับไปดูรูปที่ ๑ แล้วสังเกตุอะไรแปลก ๆ ไหม? ใช่แล้ว Michael กับ Toby เมื่อใส่ลงไปในฟังก์ชัน hash แล้วให้เลข 2 เหมือนกัน แล้วลองกลับมาดูฟังก์ชันของ hash ของเรากัน
hash(0) = 19
hash(10000) = 19
hash(20000) = 19
สิ่งนี้เรียกว่า Hash collision นั่นคือการซ้อนทัับกันของ hash ในการแข่งขันเขียนโปรแกรมแล้วเราไม่มีทางรู้ได้เลยว่าค่าที่ได้มาจะซ้อนทับกันหรือไม่ เช่นเดียวกับในโลกจริง แม้ว่าในโลกจริงจะตรวจสอบชุดข้อมูลได้ หากแต่กับโปรแกรมใหญ่ ๆ แล้ว มันก็ทำได้ยาก
การทับกันของ hash นี้ หากเป็นไปตามโค้ดข้างบนแล้ว จะทำให้ข้อมูลตัวเก่าถูกแทนที่ด้วยตัวใหม่ ส่งผลให้เกิดคำตอบที่ผิดได้ เราอาจแก้ลองปัญหาได้โดยการเปลี่ยนเลข magic ซึ่งอาจจะช่วยได้ หรือช่วยไม่ได้ แล้วแต่เวรกรรม (ไสยศาสตร์ยังไงล่ะ)
แล้วเราจะมีวิธีแก้มันอย่างไร ติดตามต่อใน Hash II : การซ้อนทับ
เข้าสู่ระบบเพื่อแสดงความคิดเห็น
Log in